大型系統入門 — 架構篇
Hey!jojo!來看一下什麼是大型系統吧

Hi, 大家好,我是 Luka,一名擁有金魚腦的後端工程師,記憶力只能持續 3 分鐘。今天來寫的是基於實戰經驗的「大型系統入門」,讓我們一起來認識大型系統吧!

大型系統到底代表什麼意思?

我朋友問我一個問題,分散式爬蟲系統算不算是一個大型系統呀?

不只在 DDOS 別人的網站,不斷幫別人的網站做壓力測試。

同時也在 DDOS 自己的資料庫

資料庫的 QPS (Query Per Second) 好高阿,但這樣算不算是大型系統呢?

爬蟲系統可能一些原因導致停止運作( Downtime ),例如:要爬的網站改版。要爬的資訊就不一樣了。其實對系統的穩定性要求沒有那麼高,如果幾個小時沒有爬,並不會怎麼樣。

我的想法是,大型系統需要提供值得信賴的服務品質。

接著正式來介紹大型系統~
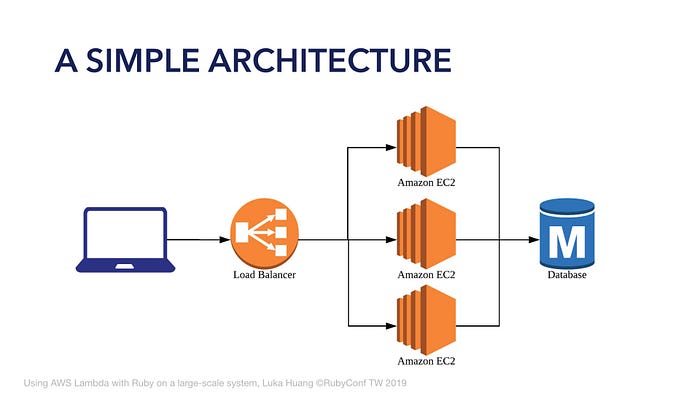
這是一個簡單的架構圖,使用者透過瀏覽器,流量經過 load balancer,分散到多台的 EC2,存取同一台 Database。每一台 EC2 都提供了完整個網站功能,這就是整體式架構 (Monolithic)。

讓它變得很快!

我想到一個好辦法,用快取!
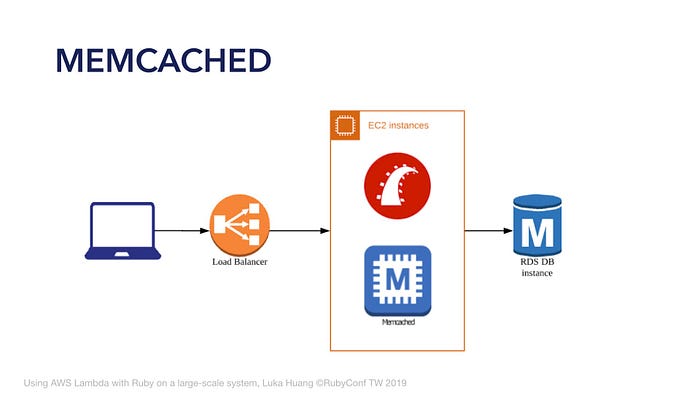
來試試看在本地端,Instance 內部加上 Memcached,對一些不常變更的資料做快取。

還要更快!

來加個 CDN
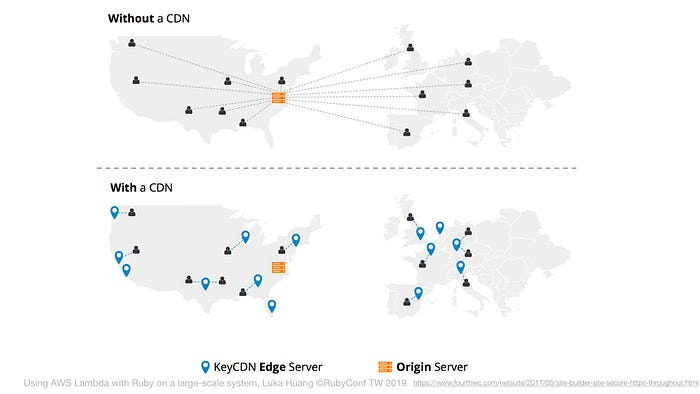
沒有加上 CDN 之前,延遲的時間就會隨著距離而增加。加上 CDN 可以有效的減少網路延遲 ( latency )。

這是加上 CDN 之後的架構圖,這邊我用 AWS 的 CloudFront 做 CDN。

接著來聊一聊資料庫
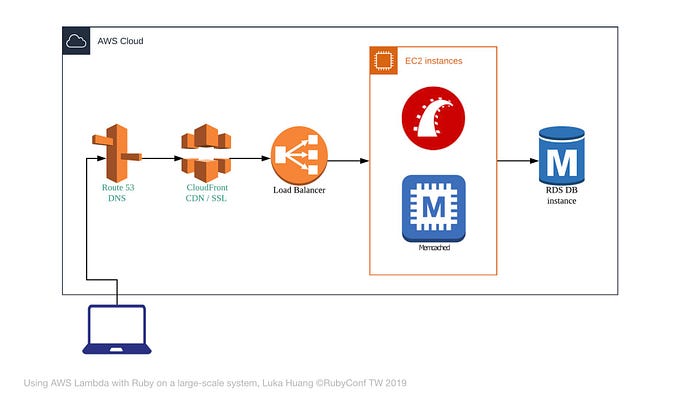
現在這個架構有什麼問題呢?
透過 Loadbalancer 分散流量到後面的機器 (instance) 後,機器可以有很多台,形成 Instance Cluster。
而 資料庫卻只有一個。所以資料庫是很珍貴的,我們要盡可能的降低 資料庫的負擔。

第一個主題 — 讀寫分離
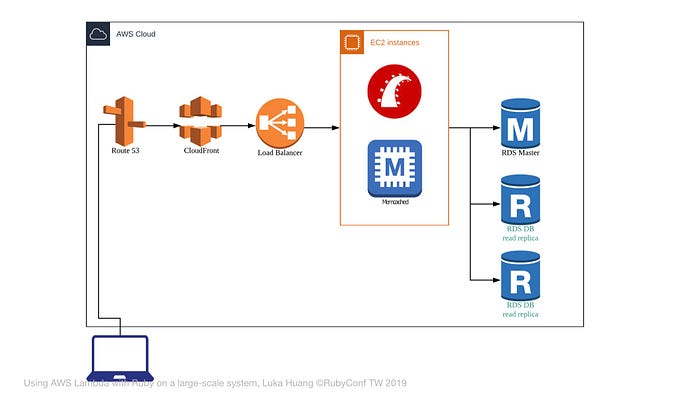
我們可以增加 Read Replica,只讀取,而不寫入。
因為大部分的需求「讀」一定遠大於「寫」
我們可以透過這種方式來降低主要資料庫 (Master Database) 的壓力。

讀寫分離是一個資料庫 Ops 的經典問題。
在上述的幾本 Database、SRE 的經典書籍中,都有很大的篇幅,來講 Master-slave 架構的運維

這是幾個讀寫分離常見的問題:
- 當延遲發生的時候,如何讓我們的服務正常運作
- 什麼時候應該用 Master 代替 Read Replica
- 各家 Database 是怎麼去實作 master-slave 的同步
這些都是值得深入探討的問題。

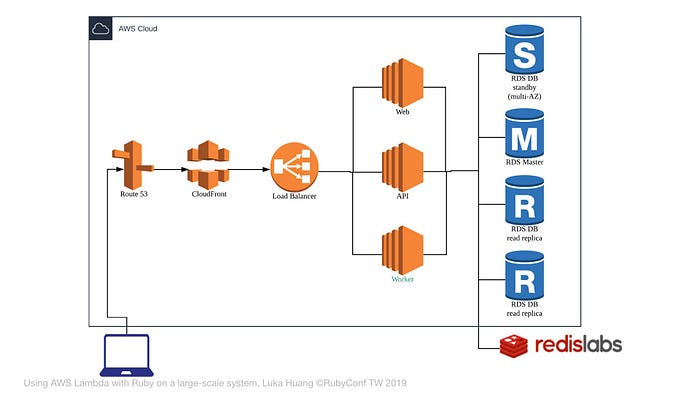
除了 Master DB 以外,為了保險,我們會有一個 Hot Standby 的 DB,如果 Master Database 壞掉,就會把流量轉到 Hot Standy DB。
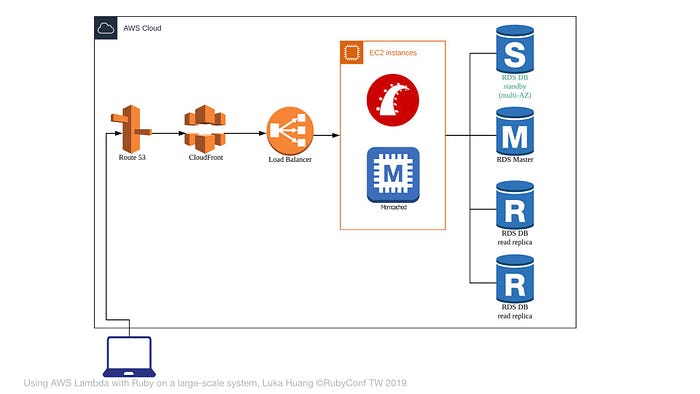
這是加上 Hot Standby DB 的架構圖

接下來的主題是 Redis
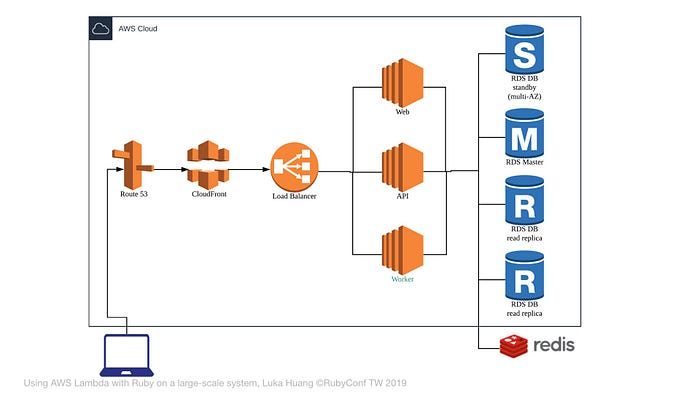
剛剛我們做的事情,增進了 Database 的 HA,但是 RDBMS 仍然只有一個,所以我們會使用 Redis 來紓解 Database 的壓力。
一些常見應用,例如:排行榜、按讚 … 等等,可以使用 Redis 來實作。
原則 — 你可以把一些允許流失的資料,放在 Redis 裡面。
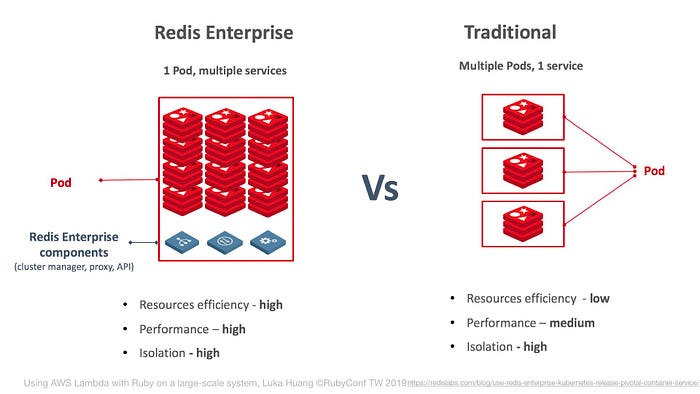
當我們要擴展 Redis 的時候,不會是只有一台 Redis,所以我們也會使用 Redis Cluster。你可以選擇自己架或是用外部服務。
RedisLab 全托管是敝公司的採用的解決方案。

接下來的主題是 Worker。

Worker 會有一個存放 Task 的地方,畫面上的是使用 AWS SQS — Simple Queue Service 來儲存 Task。

這幾種常見的 Worker,差別在於儲存 Task 的 Queue Service 選用的不同。

敝公司使用的 Queue Service 是SQS。搭配一個叫做 Shoryuken (沒錯,就是快打旋風裡面的昇龍拳) 的 Worker,目前頭好壯壯。

API Server 的效能調教
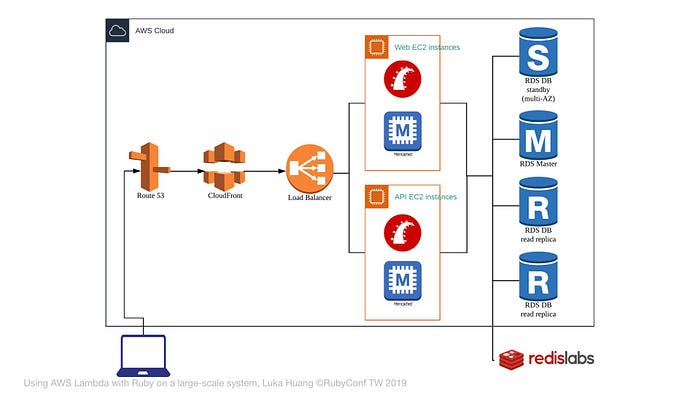
通常我們會將 instance 分為 API和 Web 兩種類型,我們就可以用一些方式,來調教效能。

可以用一些套件來加速(第一、第二項)
或是使用自訂 Middleware 來增加 API 伺服器的吞吐量 (Throughput)

接下來的主題是 Multi Region
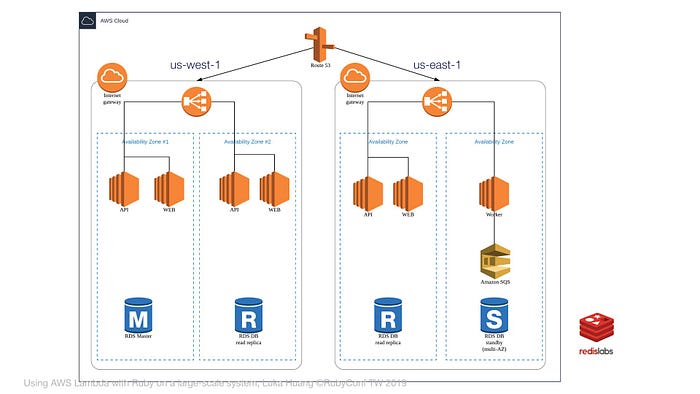
架構上如果是需要服務不同的區域,那會是完全隔離兩套,例如圖片上的是美西和美東各一套架構。資料庫分散在不同的 AZ,增加可用性。

接著來看看 Auto Scaling

如果伺服器流量比較大的時候,那麼機器的 CPU / Ram 的使用量會飆高。
這時候我們可以透過設定 Auto-scaling Group 觸發條件,來讓服務保持穩定。例如: 當 CPU 到達 70%,就會自動擴展 ( Scale ) 出新的 Auto-scaling Group。
結尾
大型系統的簡介就到這邊,初次嘗試用這種方式分享知識,不知道大家感覺怎麼樣?如果喜歡的話麻煩幫我拍個手,你的鼓勵會讓我繼續寫下去。
拍 10 下:簽到
拍 20 下:支持
拍 30 下:讚讚讚!
拍 50 下:感謝!我寫這篇文章值得了
最後附上投影片網址,作者正是金魚腦我本人。
